The Future of Data Engineering: Trends and Technologies to Watch in 2025

In the digital economy, data isn’t just valuable; it’s foundational. Every click, transaction, sensor reading, and interaction generates raw material that holds the potential for groundbreaking insights, optimized operations, and unparalleled customer experiences. But raw data, in its chaotic, voluminous state, is potential energy waiting to be harnessed. This is where data engineering steps in – the critical discipline responsible for designing, building, and maintaining the robust systems that transform this deluge of raw data into reliable, accessible, and analysis-ready assets.
At Kernshell, we live and breathe the challenges and opportunities within the data landscape. We understand that the ability to effectively engineer data infrastructure is no longer a competitive advantage; it’s a prerequisite for survival and growth. The field is evolving at breakneck speed, driven by exponential data growth (think zettabytes!), the insatiable demand for real-time insights, the rise of AI/ML, and the constant push for greater efficiency and scalability.
Staying ahead requires more than just keeping up; it demands foresight. What trends are defining the next phase of data engineering? What technologies should teams be evaluating and adopting? How is the role of the data engineer itself transforming?
This post delves into the key trends and technologies shaping the future of data engineering as we look towards 2025 and beyond. We’ll explore the shifts in architecture, tooling, processes, and mindset that are necessary to build the data platforms of tomorrow.
From Solid Foundations to Dynamic Ecosystems: The Current State
Before looking forward, it’s helpful to acknowledge the ground we stand on. Data engineering has matured significantly from the days of solely managing on-premise relational databases and nightly batch ETL jobs. Today’s landscape is largely characterized by:
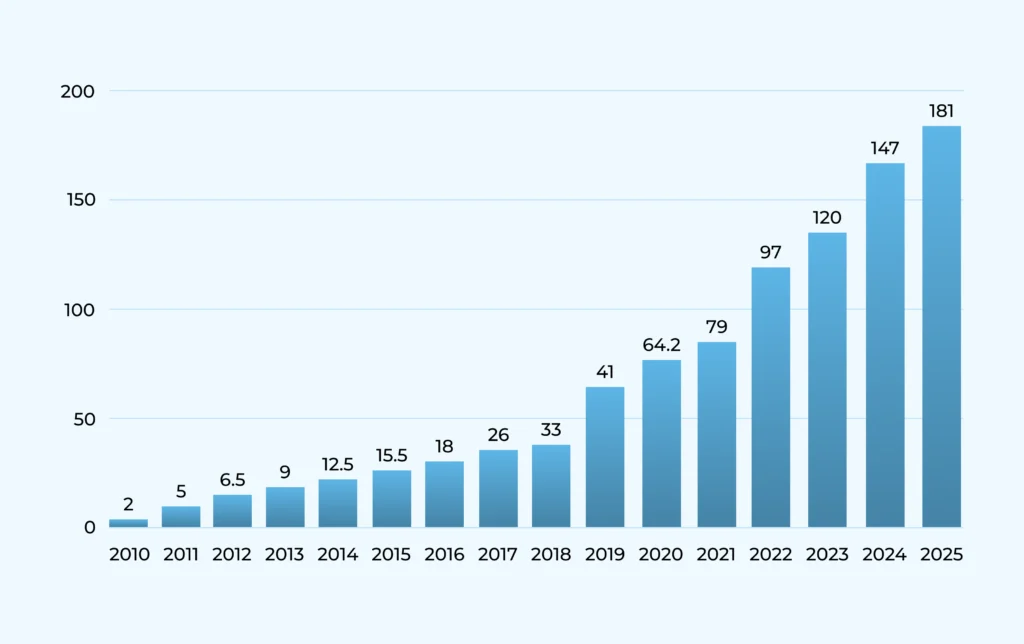
-
- Cloud Dominance: Public cloud platforms (AWS, Azure, GCP) are the default infrastructure for most modern data initiatives, offering unparalleled scalability, managed services, and cost-flexibility.
- The Lakehouse Emerges: The debate between structured data warehouses and flexible data lakes is converging towards the “Lakehouse” paradigm – architectures aiming to combine the scalability and flexibility of data lakes with the ACID transactions, governance, and performance management features of data warehouses (often using formats like Delta Lake, Iceberg, Hudi on cloud object storage).
- Sophisticated Pipelines: While ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) remain core concepts, the tools and techniques for building pipelines are far more advanced, incorporating orchestration frameworks (Airflow, Dagster, Prefect), transformation tools (dbt, Spark), and robust monitoring.
- Streaming Data is Mainstream: Batch processing still has its place, but the demand for real-time insights has pushed streaming technologies (Kafka, Pulsar, Flink, Spark Streaming, Kinesis) into the mainstream for use cases ranging from fraud detection to real-time analytics.
However, this foundation is constantly being reshaped by new pressures and possibilities. Let’s explore the key trends driving the next wave of evolution.
Top Data Engineering Trends to Watch in 2025

1. The Ubiquity of Real-Time & Streaming Data Architectures
While not new, the expectation of real-time data processing is becoming the norm, not the exception. Businesses demand immediate insights to react to market changes, personalize customer interactions instantaneously, and detect anomalies as they happen.
-
- Why Now? Maturing streaming technologies, lower costs of cloud streaming services, and competitive pressure make real-time feasible and necessary for more use cases.
- Impact: Data engineers need deep expertise in stream processing frameworks (Flink, Spark Streaming), message queues (Kafka, Pulsar), and designing fault-tolerant, low-latency pipelines. Architectures are shifting towards Kappa or Lambda patterns that prioritize streaming paths. Performance monitoring becomes critical.
- Technologies: Apache Kafka, Apache Pulsar, Apache Flink, Spark Structured Streaming, AWS Kinesis, Google Cloud Dataflow, stream-processing-as-a-service platforms.
- Value: Faster decision-making, real-time personalization, immediate fraud detection, operational intelligence.
2. Cloud-Native & Serverless Become Standard Practice
Data engineering is moving beyond simply using the cloud to being inherently cloud-native. This means leveraging managed services, serverless compute, containerization, and Infrastructure as Code (IaC) to build elastic, resilient, and cost-efficient data platforms.
-
- Why Now? Cloud providers offer increasingly sophisticated and integrated managed data services (databases, processing engines, orchestration, ML platforms). Serverless options mature, reducing operational overhead.
- Impact: Data engineers spend less time managing infrastructure and more time designing data flows and logic. Skills in IaC (Terraform, CloudFormation), containerization (Docker, Kubernetes), and specific cloud provider services become essential. Cost optimization becomes a key design consideration.
- Technologies: AWS Lambda/Step Functions/Glue/EMR Serverless, Azure Functions/Data Factory/Synapse Serverless, Google Cloud Functions/Cloud Run/Dataflow/Dataproc Serverless, Terraform, Kubernetes.
- Value: Reduced operational burden, faster development cycles, automatic scalability, potentially lower TCO (if managed well).
3. AI/ML Integration Within Data Engineering Workflows
AI and Machine Learning aren’t just consumers of data pipelines; they are becoming integral parts of them. AI/ML techniques are being used to automate and optimize data engineering tasks themselves.
-
- Why Now? Advancements in ML algorithms, availability of MLOps tools, and the sheer complexity of modern data environments necessitate intelligent automation.
- Impact: AI can automate data quality checks, detect schema drift, optimize query performance, suggest pipeline configurations, automate data discovery and cataloging, and even generate boilerplate ETL code. Data engineers need to understand how to leverage these tools and collaborate closely with MLOps practices.
- Technologies: AI-powered data quality tools, automated schema detection/evolution tools, intelligent monitoring/observability platforms, features within cloud data platforms, MLOps frameworks (MLflow, Kubeflow).
- Value: Increased efficiency, improved data quality, faster troubleshooting, more resilient pipelines, reduced manual toil.
4. The Rise and Maturation of the Data Lakehouse
The Lakehouse architecture is solidifying its position as a dominant paradigm. It promises the best of both worlds: the low-cost, flexible storage of a data lake combined with the reliability, governance, and performance features (like ACID transactions, time travel, schema enforcement) of a data warehouse, often built on open table formats.
-
- Why Now? Open table formats (Delta Lake, Apache Iceberg, Apache Hudi) have matured significantly, gaining wide adoption across major cloud platforms and processing engines (Spark, Flink, Trino, Snowflake, BigQuery, Redshift).
- Impact: Data engineers need to understand the principles and implementation details of these open formats. Architecture design focuses on leveraging these formats on cloud object storage (S3, ADLS, GCS). This simplifies architectures by potentially reducing the need for separate lake and warehouse systems for many use cases.
- Technologies: Delta Lake, Apache Iceberg, Apache Hudi, Databricks, Snowflake, Google BigQuery, Amazon Redshift Spectrum, Starburst/Trino, Apache Spark.
- Value: Unified analytics platform, simplified data architecture, improved data reliability and governance on the lake, cost-efficiency.
5. Data Mesh: From Concept to Practical Implementation
Data Mesh, the socio-technical approach advocating for decentralized data ownership by domain, treating data as a product, self-serve infrastructure as a platform, and federated computational governance, is moving beyond theoretical discussion into practical adoption, especially in larger, complex organizations.
-
- Why Now? Centralized data teams become bottlenecks in large enterprises. Business domains need faster access and control over their data. Platform thinking matures.
- Impact: This represents a significant organizational and architectural shift. Data engineers may become part of domain teams, building data products specific to that domain. Platform teams focus on providing the self-serve tools (storage, processing, discovery, quality) needed by domain teams. Requires strong emphasis on standards, interoperability, and federated governance.
- Technologies: Data catalogs (supporting discovery across domains), data quality frameworks, access control systems, standardized APIs/protocols for data sharing, self-service platform tooling (often built on cloud services).
- Value: Increased agility and scalability for large organizations, clearer data ownership and accountability, data closer to domain expertise, faster time-to-value for domain-specific insights.
6. Hyper-Focus on Data Governance, Security, and Privacy
As regulations tighten (GDPR, CCPA, etc.) and data breaches remain a constant threat, robust data governance, security, and privacy are non-negotiable. This is shifting from a compliance checkbox exercise to a foundational aspect of data platform design.
-
- Why Now? Increasing regulatory pressure, heightened customer awareness of data privacy, significant financial and reputational risks associated with breaches or non-compliance. The complexity of modern data stacks makes governance harder.
- Impact: Data engineers must embed security and governance controls throughout the pipeline lifecycle. This includes fine-grained access control, data encryption (at rest and in transit), data masking/anonymization for sensitive information (PII), automated data lineage tracking, and integration with central data catalogs and governance policies. Collaboration with security and compliance teams is essential.
- Technologies: Cloud provider IAM/security services, data cataloging tools (Alation, Collibra, DataHub, Amundsen), data masking/encryption tools, data lineage platforms, policy enforcement engines (OPA).
- Value: Reduced risk of breaches and fines, increased trust (internal and external), compliance assurance, better data understanding and discoverability.
7. Data Observability: Beyond Monitoring to Deep Understanding
Monitoring tells you if a pipeline failed; Data Observability aims to tell you why. It involves gaining deep visibility into the health and state of data systems by monitoring not just infrastructure metrics but also data quality, pipeline execution, schema changes, and lineage – often referred to as the pillars: metrics, logs, traces, data quality, and lineage.
-
- Why Now? The complexity of modern, distributed data systems makes troubleshooting difficult. Silent data failures (pipelines run but data is wrong) are insidious. Need for proactive detection and faster root cause analysis.
- Impact: Data engineers need to instrument pipelines and platforms thoroughly to emit the necessary signals. Specialized data observability tools are emerging to correlate information across pillars, helping teams quickly understand data incidents, track data quality degradation, and understand the impact of schema changes.
- Technologies: Dedicated Data Observability platforms (Monte Carlo, Acceldata, Databand, Soda), integration of monitoring tools (Datadog, Dynatrace) with data quality tools (Great Expectations) and lineage information.
- Value: Faster incident detection and resolution, reduced data downtime, increased data trust and reliability, proactive identification of data quality issues.
8. DataOps Culture and Automation Take Root
Borrowing principles from DevOps, DataOps focuses on automating and streamlining the processes around data pipeline development, testing, deployment, and management, emphasizing collaboration between data engineers, analysts, data scientists, and operations.
-
- Why Now? Manual processes are slow, error-prone, and unscalable. Need for faster iteration cycles and more reliable data delivery. Complexity requires better collaboration and automated workflows.
- Impact: Increased use of CI/CD practices for data pipelines (automated testing, version control for code and configuration, automated deployments). Emphasis on monitoring, alerting, and feedback loops. Fosters a culture of shared responsibility for data quality and reliability.
- Technologies: CI/CD tools (Jenkins, GitLab CI, GitHub Actions), orchestration tools (Airflow, Dagster), testing frameworks (dbt test, Great Expectations), version control (Git), infrastructure as code (Terraform).
- Value: Increased development velocity, improved pipeline reliability, better collaboration, reduced errors, faster recovery from failures.
The Evolving Role of the Data Engineer
These trends are not just changing the technology stack; they are reshaping the role of the data engineer. In 2025, the successful data engineer will be:
-
- More of a Platform Enabler: Less focused on building bespoke pipelines for every request, and more on building robust, self-service platforms and tools that empower analysts and data scientists.
- Cross-Functional Collaborator: Working closely with data scientists, ML engineers, analysts, security teams, and business domain experts. Understanding their needs is crucial.
- Automation Advocate: Constantly seeking opportunities to automate manual tasks related to infrastructure, testing, deployment, and monitoring.
- Quality and Governance Champion: Taking ownership of data quality, security, and compliance within their domain or platform.
- Lifelong Learner: The pace of change requires continuous learning to stay current with new technologies, patterns, and best practices.
The demand for skilled data engineers remains incredibly high, reflecting their pivotal role in unlocking data’s value.
Preparing for the Data Engineering Future at Kernshell
Navigating this evolving landscape requires a strategic approach. At Kernshell, we believe organizations should focus on:
-
- Building Strong Foundations: Invest in scalable cloud infrastructure, robust governance frameworks, and core automation capabilities.
- Strategic Technology Adoption: Evaluate new trends and tools based on genuine business needs and potential ROI, not just hype. Start with pilot projects.
- Investing in Skills: Upskill existing teams and hire for the evolving skillset required – including cloud-native expertise, streaming concepts, automation, and governance awareness.
- Fostering Collaboration: Break down silos between data engineering, data science, analytics, and operations teams. Embrace DataOps principles.
- Prioritizing Data Trust: Make data quality, observability, and security central tenets of your data strategy.
 Conclusion:
Conclusion:
The future of data engineering in 2025 is dynamic, complex, and incredibly exciting. Trends like real-time processing, cloud-native architectures, AI integration, the Lakehouse paradigm, Data Mesh principles, heightened governance, observability, and DataOps automation are fundamentally changing how we build and manage data platforms.
For organizations like those Kernshell serves, embracing these changes strategically is key to transforming data from a raw resource into a powerful engine for innovation, efficiency, and competitive differentiation. The data engineers who master these evolving technologies and adapt their mindset will be the architects building the truly data-driven enterprises of tomorrow. The blueprint is emerging – it’s time to start building.