













Anatomy of RAG: Retriever, Generator, and the Workflow | Complete Technical Guide 2026

What is RAG in 2026?
Retrieval-Augmented Generation (RAG) is an AI architecture that enhances Large Language Model (LLM) responses by first retrieving relevant documents from a knowledge base and then using those documents as context for the LLM’s generation step. RAG addresses the core limitation of standalone LLMs — their knowledge is fixed at training time and doesn’t include your specific organizational data.
Retrieval-Augmented Generation (RAG) has emerged as the definitive solution for building accurate, reliable AI applications. But what makes RAG so powerful?
The answer lies in its elegant architecture, a sophisticated interplay between retrievers, generators, and intelligent workflows that transform how AI systems access and utilize knowledge.
Understanding the anatomy of RAG is crucial for AI engineers, data scientists, and enterprise teams implementing next-generation AI solutions. This comprehensive guide dissects each component, revealing how they work together to create intelligent, context-aware AI systems.
The Three Pillars of RAG Architecture
RAG is a hybrid framework that integrates a retrieval mechanism with a generative model to improve the contextual relevance and factual accuracy of generated content. This architecture consists of three fundamental components:
-
- The Retriever: The intelligent search engine that finds relevant information
- The Generator: The large language model that produces responses
- The Knowledge Base: The vector database storing indexed information
Each component plays a critical role in ensuring accurate, contextual responses that minimize AI hallucinations and maximize reliability.
Component Functions and Requirements
Each component in a RAG system serves a specific purpose and has distinct operational requirements:
| Component | Function | Requirements |
| Data Ingestion | Load and preprocess documents into smaller chunks | Access to structured and unstructured data sources; document parsing tools |
| Embedding Model | Convert text chunks and queries into vector representations | Pre-trained embedding model; sufficient compute resources |
| Vector Database | Store and index embeddings for efficient searches | Scalable vector database (e.g., Pinecone, Milvus); effective indexing |
| Retrieval Engine | Perform similarity searches to find relevant passages | Fast similarity search capabilities; relevance ranking algorithms |
| Prompt Augmentation | Format retrieved context with user queries | Effective prompt engineering; robust context management |
| Generation Model | Generate responses using the augmented prompt | Access to LLM APIs; reliable response formatting and post-processing |
Component 1: The Retriever – Your AI’s Research Assistant
The retriever is the first line of defense against AI hallucinations. Instead of relying solely on the model’s pre-trained knowledge, RAG retrieves relevant information from connected data sources and uses it to generate a more accurate and context-aware response.
How Retrievers Work
Step 1: Query Understanding
When a user submits a query, the retriever doesn’t just perform keyword matching. It employs sophisticated natural language understanding to:
-
- Parse the user’s intent and context
- Identify key concepts and entities
- Generate query embeddings (vector representations)
- Determine the semantic meaning behind the question
Step 2: Semantic Search Execution
Modern semantic search uses sentence embeddings, which are mathematical representations that capture semantic meaning and context in high-dimensional vector space. The retriever:
-
- Converts the query into a high-dimensional vector (typically 384-1536 dimensions)
- Performs similarity searches across the vector database
- Uses cosine similarity or other distance metrics to find matches
- Ranks results by relevance scores
Step 3: Hybrid Search Optimization
Advanced RAG systems combine multiple search strategies:
-
- Dense retrieval: Vector similarity for semantic understanding
- Sparse retrieval: Keyword matching for exact term precision
- Metadata filtering: Contextual constraints (date, source, category)
- Reranking: Post-retrieval scoring to optimize results
Types of Retriever Models
Bi-Encoder Retrievers
-
- Encode queries and documents independently
- Fast, efficient similarity searches
- Examples: Sentence-BERT, MPNet, E5
Cross-Encoder Retrievers
-
- Jointly encode query-document pairs
- Higher accuracy but computationally expensive
- Used for reranking top results
Hybrid Retrievers
-
- Combine dense and sparse methods
- Balance precision and recall
- Industry standard for production systems

Component 2: The Vector Database – Your AI’s Memory System
Vector databases power Retrieval Augmented Generation tasks, which allow you to bring additional context to LLMs by using the context from a vector search to augment the user prompt.
Understanding Vector Databases
Vector databases are specialized storage systems optimized for high-dimensional vector operations. Unlike traditional databases that store structured data, vector databases store embeddings—numerical representations that capture semantic meaning.
Key Features of Vector Databases
1. Efficient Similarity Search
-
- ANN (Approximate Nearest Neighbor) algorithms
- Sub-linear search complexity
- Millisecond query response times
- Handles millions to billions of vectors
2. Indexing Strategies
-
- HNSW (Hierarchical Navigable Small World): Fast, memory-efficient
- IVF (Inverted File Index): Partitioned search spaces
- LSH (Locality-Sensitive Hashing): Probabilistic matching
- Product Quantization: Compressed representations
3. Metadata Management
-
- Filterable attributes (source, date, author)
- Hybrid search capabilities
- Role-based access control
- Version tracking and updates
Popular Vector Database Solutions
Production-Grade Options:
-
- Pinecone: Fully managed, serverless
- Weaviate: Open-source, GraphQL API
- Qdrant: High-performance, Rust-based
- Milvus: Scalable, distributed architecture
- ChromaDB: Developer-friendly, embedded option
- Postgres with pgvector: SQL + vector search
The Indexing Process
Data Preparation:
-
- Document chunking (256-512 token segments)
- Overlap strategies for context preservation
- Metadata extraction and tagging
- Quality validation and cleaning
Embedding Generation:
-
- Select appropriate embedding model
- Batch processing for efficiency
- Dimensionality optimization
- Normalization and standardization
Database Population:
-
- Upsert vectors with metadata
- Build optimized indexes
- Configure similarity metrics
- Enable hybrid search parameters

Component 3: The Generator – Your AI’s Communication Expert
The generator is the large language model (LLM) that synthesizes retrieved information into coherent, contextual responses. While retrievers find information, generators make it understandable and actionable.
Generator Responsibilities
Context Integration
The generator receives:
-
- User query
- Retrieved document chunks (typically 3-10 passages)
- System prompts and instructions
- Metadata and source citations
Response Synthesis
The LLM then:
-
- Analyzes retrieved context for relevance
- Extracts key information and facts
- Synthesizes coherent answers
- Maintains conversational flow
- Includes proper citations
Popular Generator Models
Closed-Source Options:
-
- GPT-4o, GPT-4 Turbo (OpenAI)
- Claude 4 Sonnet, Opus (Anthropic)
- Gemini Pro, Ultra (Google)
Open-Source Alternatives:
-
- Llama 3.1, 3.2 (Meta)
- Mistral Large, Medium (Mistral AI)
- Mixtral 8x7B (Mixture of Experts)
- Phi-3 (Microsoft)
Prompt Engineering for RAG
Effective generators require carefully crafted prompts:
System: You are a helpful assistant. Answer questions based ONLY on the
provided context. If the answer isn’t in the context, say “I don’t have
enough information to answer that.”
Context: {retrieved_documents}
User Question: {user_query}
Instructions:
-
- Use only information from the context
- Cite sources when possible
- Be concise and accurate
- Acknowledge limitations
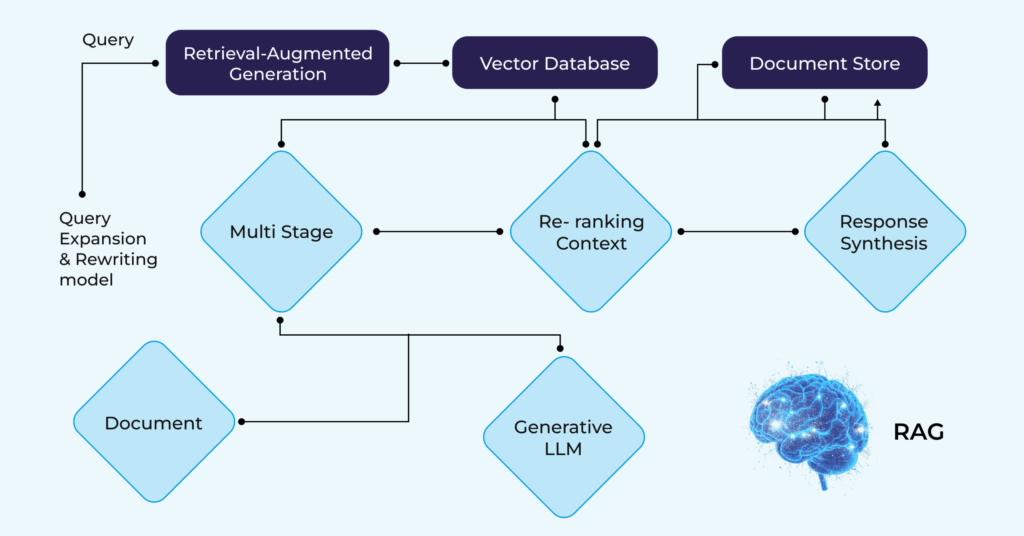
The Complete RAG Workflow: Step-by-Step
The RAG workflow involves data loading into a source like a vector database, retrieval of relevant data based on user query, and augmentation where retrieved data and user query are combined into a prompt.
Phase 1: Indexing (Offline Process)
1. Data Ingestion
-
- Collect documents from various sources
- Support multiple formats (PDF, DOCX, HTML, JSON)
- Extract text and structural information
- Handle multimedia content appropriately
2. Document Processing
-
- Clean and normalize text
- Remove boilerplate and redundant content
- Split into optimal chunk sizes
- Preserve semantic boundaries (paragraphs, sections)
3. Embedding Generation
-
- Convert chunks to vector embeddings
- Use consistent embedding models
- Batch process for efficiency
- Store embeddings with metadata
4. Database Population
-
- Index vectors in the database
- Configure search parameters
- Optimize for query performance
- Implement backup and versioning
Phase 2: Retrieval (Runtime Process)
1. Query Reception The user submits a prompt, which triggers the information retrieval component to gather relevant information and feed that to the generative AI model.
2. Query Embedding
-
- Convert user query to vector representation
- Use same embedding model as indexing
- Apply query preprocessing if needed
3. Similarity Search
-
- Execute vector similarity search
- Apply metadata filters
- Retrieve top-k relevant chunks (typically k=5-10)
- Calculate relevance scores
4. Result Reranking (Optional)
-
- Apply cross-encoder for precision
- Consider recency and source authority
- Remove near-duplicate results
- Optimize for diversity
Phase 3: Augmentation (Runtime Process)
1. Context Construction
-
- Combine retrieved chunks
- Add metadata and citations
- Structure context logically
- Respect token limits
2. Prompt Assembly
-
- Integrate system instructions
- Include user query
- Add retrieved context
- Specify output format
3. Generation
-
- Send augmented prompt to LLM
- Apply temperature and sampling parameters
- Stream response for better UX
- Monitor for hallucinations
Phase 4: Post-Processing (Runtime Process)
1. Response Validation
-
- Verify factual consistency
- Check citation accuracy
- Ensure appropriate tone
- Validate completeness
2. Source Attribution
-
- Link claims to source documents
- Provide document snippets
- Enable user verification
- Maintain transparency
3. User Delivery
-
- Format response appropriately
- Include confidence scores
- Offer source links
- Enable follow-up questions
Advanced RAG Patterns and Optimizations
1. Hierarchical RAG
Implement multi-level retrieval:
-
- Document-level retrieval first
- Chunk-level retrieval second
- Section-level context preservation
2. Iterative RAG
Enable multi-turn refinement:
-
- Initial retrieval and generation
- Query reformulation based on gaps
- Additional retrieval rounds
- Synthesis of multiple contexts
3. Agentic RAG
Incorporate decision-making logic:
-
- Route queries to appropriate sources
- Determine when to search external APIs
- Combine multiple retrieval strategies
- Validate and cross-reference information
4. Multimodal RAG
Extend beyond text:
-
- Image embedding and retrieval
- Audio transcription and indexing
- Video frame analysis
- Cross-modal search capabilities
Performance Optimization Strategies
Retrieval Optimization
Chunk Size Tuning
-
- Test 256, 512, 1024 token chunks
- Balance context vs. precision
- Consider domain-specific requirements
Overlap Strategies
-
- Implement 10-20% overlap
- Preserve context across boundaries
- Reduce information fragmentation
Top-k Configuration
-
- Start with k=5-10
- Monitor precision-recall tradeoffs
- Adjust based on query complexity
Generation Optimization
Context Window Management
-
- Prioritize most relevant chunks
- Truncate intelligently
- Summarize when necessary
Temperature Tuning
-
- Lower (0.3-0.5) for factual responses
- Higher (0.7-0.9) for creative tasks
- Domain-specific calibration
Streaming Responses
-
- Improve perceived latency
- Enable early termination
- Better user experience
Monitoring and Evaluation
Key Metrics
Retrieval Quality
-
- Precision@k: Relevant results in top-k
- Recall@k: Coverage of relevant information
- MRR (Mean Reciprocal Rank): Position of first relevant result
- NDCG (Normalized Discounted Cumulative Gain): Ranking quality
Generation Quality
-
- Faithfulness: Alignment with retrieved context
- Answer Relevance: Response addresses query
- Context Precision: Use of relevant information
- Hallucination Rate: Fabricated information frequency
System Performance
-
- End-to-end latency
- Throughput (queries per second)
- Resource utilization
- Cost per query
Real-World Implementation Considerations
Scalability
-
- Start with 100K-1M documents
- Plan for horizontal scaling
- Implement caching strategies
- Optimize database indexes
Security & Privacy
-
- Implement access controls
- Encrypt vectors and metadata
- Audit retrieval operations
- Comply with data regulations (GDPR, HIPAA)
Cost Management
-
- Balance model size vs. accuracy
- Implement efficient caching
- Optimize embedding dimensions
- Use appropriate infrastructure
Maintenance
-
- Regular knowledge base updates
- Monitor drift and performance
- Retrain or fine-tune models
- Version control for reproducibility
The Future of RAG Architecture
Emerging trends shaping RAG evolution:
1. Adaptive Retrieval
-
- Dynamic k-selection based on query complexity
- Confidence-based retrieval depth
- Query complexity classification
2. Self-Reflective RAG
-
- Generators evaluate retrieval quality
- Automatic query reformulation
- Iterative improvement loops
3. Knowledge Graph Integration
-
- Structured + unstructured retrieval
- Relationship-aware search
- Multi-hop reasoning capabilities
4. Edge RAG
-
- On-device vector databases
- Privacy-preserving retrieval
- Reduced latency architectures
Conclusion: Mastering RAG Architecture
Understanding the anatomy of RAG—retrievers, generators, and the workflow connecting them—is fundamental to building production-grade AI applications. Each component plays a critical role:
-
- Retrievers find the needle in the haystack through semantic search
- Vector Databases organize and serve knowledge efficiently
- Generators synthesize information into human-understandable responses
- The Workflow orchestrates these components seamlessly
As RAG technology continues evolving, mastering these fundamentals positions you to leverage advanced patterns, optimize performance, and build AI systems that users can truly trust.
Whether you’re building customer service chatbots, research assistants, or enterprise knowledge management systems, understanding RAG’s anatomy is your foundation for success in the AI-driven future.

Key Takeaway
This technical guide dissects the RAG architecture component by component: the Document Processing pipeline (ingestion, chunking, embedding, indexing), the Retrieval component (vector similarity search, BM25 keyword search, hybrid retrieval, reranking), the Generation component (context assembly, prompt construction, LLM generation, citation tracking), and the Evaluation framework (retrieval accuracy, answer faithfulness, context precision). Advanced RAG techniques covered include query expansion, hypothetical document embeddings (HyDE), self-RAG, and agentic RAG.
This article was originally published on the Kernshell blog. Read the full version on Medium: Anatomy of RAG: Retriever, Generator, and the Workflow